Guide : Tout savoir sur le crawler en SEO
Pour appréhender pleinement la fonction du crawler, revenons sur le mécanisme essentiel des moteurs de recherche, à commencer par Google. Ces plateformes déploient de minuscules robots, des programmes informatiques, pour explorer l’étendue du web. Ces bots naviguent à travers les sites en empruntant les liens qu’ils rencontrent, les considérant comme des portes d’entrée. À la différence des robots de Google, les crawlers, ou logiciels de crawl, sont sous notre commandement en tant qu’éditeurs de sites ou référenceurs.
Ces robots reproduisent le comportement des moteurs de recherche, programmés pour explorer nos sites ou ceux de nos concurrents. Le crawl peut être général sur un site entier ou ciblé sur des pages spécifiques. Son objectif est d’identifier les anomalies structurelles, évaluer les performances et analyser les liens entrants. Ces données, croisées avec les logs, offrent une mine d’informations pour les propriétaires de sites. Bien que le crawler soit souvent associé au référencement naturel, d’autres types de crawlers, notamment utilisés par les équipes marketing, méritent également l’attention.
Définition : qu’est-ce qu’un crawler en SEO ?
Un « crawler », également appelé « spider » ou « robot d’indexation », est un acteur automatisé essentiel au fonctionnement des moteurs de recherche. Sa mission : explorer vos pages web, indexant et analysant chaque page qu’il rencontre. Cependant, ce terme générique cache une dualité fondamentale : certains crawlers sont sous notre contrôle direct par contre ils n’ont pas la faculté d’indexer car ils ne sont en aucun cas liés à quelconque moteur de recherche. Tandis que d’autres évoluent de manière autonome, échappant à notre influence.
Le crawler autonome
Parmi les représentants les plus notables de cette catégorie figure le redoutable « Googlebot« . Ce robot d’exploration, déployé par le géant Google, opère en toute autonomie. En tant que référenceur, nous ne pouvons pas dicter son itinéraire ou influencer son comportement. Il s’immisce dans les recoins du web, évaluant chaque site rencontré selon des critères de pertinence et de qualité définis par les algorithmes de Google.
De même, le « robot Bing » de Microsoft, jouant un rôle similaire, explore le web indépendamment des volontés des référenceurs.
Le crawler sous contrôle
À l’opposé, certains crawlers sont comme des marionnettes que nous manipulons. À l’aide d’outils dédiés, les éditeurs de sites et les référenceurs peuvent programmer ces robots pour explorer spécifiquement leur site ou celui de leurs concurrents. Ces « crawlers commandés » permettent un contrôle fin sur le processus d’exploration, offrant des insights précieux sur la structure, la performance et les liens d’un site.
Comment fonctionne un crawler ?
Nous allons nous attarder sur le processus des crawler des moteurs de recherche. Il commence généralement par la découverte d’une nouvelle page via des liens. Le crawler suit ces liens de manière systématique, explorant ainsi le réseau web de manière organique. Une fois sur une page, le crawler analyse son contenu, extrait les liens supplémentaires et répète le processus. Cette opération continue de manière cyclique, permettant au moteur de recherche d’actualiser constamment son index.
Focus sur le Googlebot
Lorsqu’il s’agit de crawlers, le Googlebot occupe une place prépondérante. En tant que pièce maîtresse de l’algorithme de recherche de Google, son rôle est d’une importance cruciale dans le classement des pages web. Voici les différentes étapes que peut avoir un crawler :
- Phase de découverte :
Le Googlebot commence par la phase de découverte, où il identifie de nouvelles pages à explorer. Cela se fait par le biais de plusieurs sources, notamment les sitemaps soumis par les référenceurs, les liens trouvés sur d’autres sites et les données des index précédents. - Exploration et analyse du contenu :
Une fois une page découverte, le Googlebot explore son contenu de manière méthodique. Il analyse le texte, les images et d’autres éléments pour comprendre la nature et le sujet de la page. Les algorithmes sont utilisés pour interpréter le contexte et évaluer la qualité du contenu. Si nous gardons l’exemple de Google, nous avons par exemple Google Panda qui peut intervenir. - Suivi des liens :
Le Googlebot suit ensuite les liens internes et externes présents sur la page, élargissant ainsi son champ d’exploration. Cette méthode permet à Google de cartographier efficacement la structure du site web en question et de découvrir de nouvelles pages. - Fréquence de visite :
La fréquence de visite du Googlebot dépend de divers facteurs tels que la fréquence de mise à jour du contenu d’une page. Les pages fréquemment mises à jour peuvent être explorées plus régulièrement, assurant ainsi une indexation actualisée. Toute cette partie tourne autour du budget crawl.
Qu’est-ce que le budget de crawl ?
Le budget de crawl représente la capacité qu’un moteur de recherche alloue à explorer et indexer le contenu d’un site web sur une période donnée. En d’autres termes, c’est la quantité d’informations qu’un moteur de recherche, tel que Google, est prêt à « lire » sur votre site à chaque visite de son crawler.
Quelle est l’importance du budget crawl ?
Le budget de crawl représente l’allocation de ressources que les moteurs de recherche dédient à l’exploration et à l’indexation d’un site web. Comprendre son rôle est essentiel, car il influence directement la visibilité d’un site dans les résultats de recherche.
- Focalisation sur le Contenu clé :
Un budget de crawl bien géré garantit que les moteurs de recherche se concentrent sur les pages les plus importantes de votre site. Cela signifie que le contenu stratégique est exploré régulièrement, optimisant ainsi sa présence dans l’index des moteurs de recherche. - Impact sur le classement SEO :
La gestion du budget de crawl n’est pas uniquement technique, elle influe sur le classement SEO. Une exploration efficace du contenu renforce la pertinence perçue par les moteurs de recherche, contribuant ainsi positivement au positionnement dans les résultats de recherche. - Indexation rapide des nouvelles page :
Un budget de crawl optimisé garantit une indexation rapide des nouvelles pages. Cela permet aux nouveaux contenus d’être rapidement accessibles aux utilisateurs, améliorant ainsi leur visibilité dès leur apparition.
En conclusion, le budget de crawl n’est pas simplement une composante technique, mais plutôt un élément stratégique crucial du référencement. Sa gestion efficace contribue directement à la visibilité, au classement et à l’adaptabilité d’un site dans l’univers complexe des moteurs de recherche. Ignorer son importance serait négliger une opportunité essentielle pour optimiser la position de votre site en tant que ressource de confiance dans votre domaine.
Quelques stratégies pour optimiser le Budget de Crawl
- Fréquence de mise à jour :
Les pages régulièrement mises à jour retiennent l’intérêt des moteurs de recherche. Un contenu dynamique et évolutif incite les crawlers à revisiter fréquemment, tirant ainsi parti du budget de crawl de manière optimale. Des systèmes de publication réguliers et des flux RSS bien configurés peuvent favoriser cette dynamique. - Avoir un bon maillage interne :
Ce réseau de liens internes agit comme le guide du crawler, influençant directement la manière dont les moteurs de recherche explorent et indexent votre contenu - Liens internes et externes :
Une architecture de lien bien conçue, tant en interne qu’en externe, influence directement le budget de crawl. Les liens internes guident les crawlers vers les pages essentielles, tandis que les liens externes renforcent l’autorité du site. L’utilisation de liens avec des attributs « nofollow » peut être stratégique pour diriger le crawl vers des zones spécifiques du site. - Avoir un sitemap et un plan de site HTML :
Il permet de faciliter l’indexation et l’analyse de votre site - Avoir une bonne profondeur de site
Comment crawler un site web ?
Vous pouvez crawler un site web grâce à de nombreux outils. Les outils en questions vont vous permettre de collecter des données essentielles pour évaluer la santé de votre site et optimiser votre référencement.
Lorsqu’il s’agit de crawler un site web avec une précision chirurgicale, l’expertise et les outils adéquats sont des éléments essentiels. Décortiquons cette démarche avec des solutions et des outils phares, tels que Screaming Frog et SEMrush.
Solution 1 : Screaming Frog

Screaming Frog, un incontournable dans l’arsenal du SEO, offre une interface conviviale et des fonctionnalités puissantes. Cette application de crawling permet d’analyser chaque recoin d’un site, identifiant les erreurs, les liens rompus, et les problèmes d’indexation.
- Analyse des balises : Screaming Frog explore les balises méta de chaque page, offrant une vision détaillée des titres et descriptions, cruciales pour l’optimisation des moteurs de recherche.
- Détection des 404 : L’outil identifie efficacement les erreurs 404, préservant ainsi l’expérience utilisateur et optimisant le SEO et le crawl des moteurs de recherche.
- Extraction des Données Structurées : Screaming Frog excelle dans l’extraction des données structurées, facilitant la compréhension de la hiérarchie du site par les moteurs de recherche. (profondeur du site…)
Solution 2 : SEMrush

SEMrush intègre également des fonctionnalités de crawling avancées. L’outil va au-delà de l’exploration basique, offrant une analyse complète de la santé du site et de son potentiel SEO.
- Audit de site : SEMrush réalise un audit exhaustif, identifiant les problèmes de SEO on-page, de performance, et de sécurité.
- Analyse des backlinks : En scrutant les backlinks, SEMrush évalue la qualité des liens pointant vers le site, crucial pour le classement dans les résultats de recherche.
- Suivi des positions : L’outil surveille les positions des mots-clés, fournissant des insights précieux pour ajuster la stratégie de contenu.
Conseille pour optimisé le crawl d’un site web
- Définir des paramètres de crawl : Avant de lancer l’exploration, définissez des paramètres spécifiques pour cibler les pages cruciales et éviter les zones non essentielles.
- Prioriser la vitesse et l’efficacité : Optez pour des outils offrant des options pour régler la vitesse de crawl, permettant une exploration rapide et efficace.
- Gérer les balises robots.txt : Assurez-vous que votre fichier robots.txt est correctement configuré pour autoriser le crawl des parties essentielles du site.
Quel est l’importance du crawl dans une statégie SEO ?
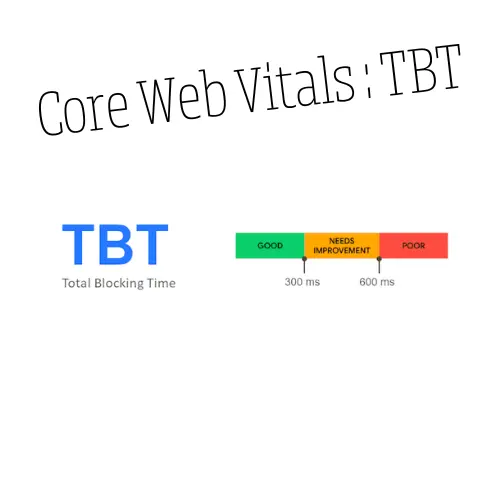
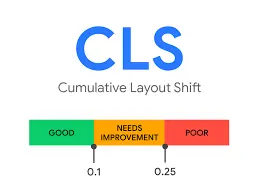
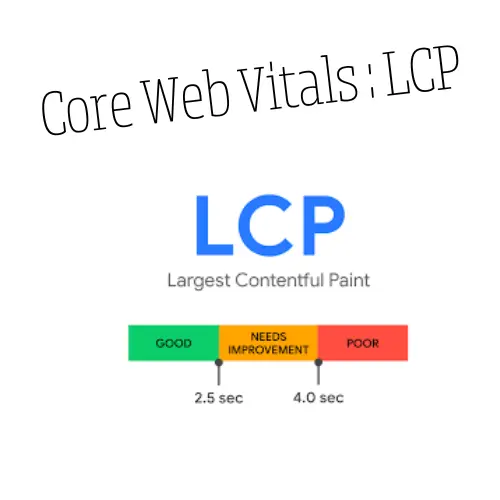
Le crawl est essentiel dans une stratégie SEO complète, dévoilant des insights inestimables. Il vous permet de faire un audit complet de votre site web. Il révèle la qualité des backlinks, façonnant l’autorité du site. Dans la dimension sémantique, le crawl décrypte le langage du site, identifiant les mots-clés stratégiques et optimisant la pertinence. Sur le front technique, il dévoile la mécanique interne, scrutant les balises méta, les redirections, les erreurs http et les core web vitals.
Enfin, L’utilisation judicieuse d’un crawler externe devient impérative pour analyser les liens externes, améliorer le profil de liens, et contrer les pratiques douteuses. En somme, le crawl n’est pas simplement une étape, mais la clé pour une stratégie SEO robuste.
Les articles qui peuvent vous intéresser :




Tombé dans le SEO depuis deux ans et avec une expérience dans le domaine, Souleymane optimise la visibilité en ligne des entreprises et des entrepreneurs. Doté d’une compréhension des algorithmes de recherche, il apporte une approche stratégique et personnalisée à chaque projet. Souleymane partage ses connaissances à travers diverses articles.